起因 最近在看crafting interpreters,书中在处理表达式结构时,讲到了面向对象编程和函数式编程的优劣,最后在取舍下用到了访问者模式,这个模式让没有系统学过编程思想的我很困惑,于是了解了一下背后的设计思想
问题是什么
我们可以将所有这些内容整合到一个包含任意子类列表的 Expression 类中。有些编译器会这么做。但我希望充分利用Java的类型系统。所以我们将为表达式定义一个基类。然后,对于每一种表达式——expression下的每一个生成式——我们创建一个子类,这个子类有该规则所特有的非终止符字段。这样,如果试图访问一元表达式的第二个操作数,就会得到一个编译错误。
在解决问题之前,先搞明白问题是什么
所以这就把问题变成了如何描述一组子类以及子类中所持有的方法,同时保持代码的逻辑性和可拓展性
如果我们为每一个操作的表达式类中添加实例方法,就会将一堆不同的领域混在一起。这违反了关注点分离原则,并会产生难以维护的代码。
作者认为在这种情况下向表达式类中添加实例方法并不合适。因为表达式这个数据是一个中间状态,他被前期的解析器创建,而被后期的解释器消费,如果要在表达式类中添加实例方法,会导致其中混淆了解析器和解释器所需要的方法
了解情况 面向对象
这样在新增一个类的时候,我们不需要更改以前的任何代码,只需要关注新的类和方法实现,我们可能会声明一个新类,将其放在一个独立的文件中,所有变更都完全独立于原来的代码
但是在新增一个操作时,我们需要更改每一个类的代码,比如在doc.cpp中dog类新增一个函数,再去cat.cpp中cat类新增一个函数,我们代码的变更会涉及到很大的范围。这还只是新增方法,当我们需要更改类的方法时,可想而知会有多么的灾难
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <cstdio> struct pet { char *m_name; int m_age; virtual void speak () }; class dog : pet{ dog (char *name, int age) { m_name = name; m_age = age; } void speak () { printf ("woof" ); } }; class cat : pet{ cat (char *name, int age) { m_name = name; m_age = age; } void speak () { printf ("meow" ); } };
函数式
这种情况下,你想要增加一个新操作变的相当简单,你只需要考虑把他放在新的原文件或是现有的文件中,代码的更改也相对集中,同时不会破坏其他的大部分函数逻辑
但是当你需要增加一个新类型,你会需要更改pet定义,所有的操作函数,在一大堆的switch case中加上新的类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <stdio.h> typedef enum { DOG, CAT } pet_type; typedef struct { pet_type type; char *m_name; int m_age; } pet; void speak (pet *speak_pet) { switch (speak_pet->type) { case DOG: printf ("woof" ); return ; case CAT: printf ("meow" ); return ; } }
解决方案 既然作者说了对于表达式的处理上,他不想用纯粹的面向对象,以避免表达式类中方法属于解析器还是解释器的混乱,那接下来就是在java中找到一个避免面向对象的方法,他采取了访问者模式
访问者模式像是一个在主要面向对象语言中强行拆分类和方法以达到折中的方案,接下来我会解释为什么
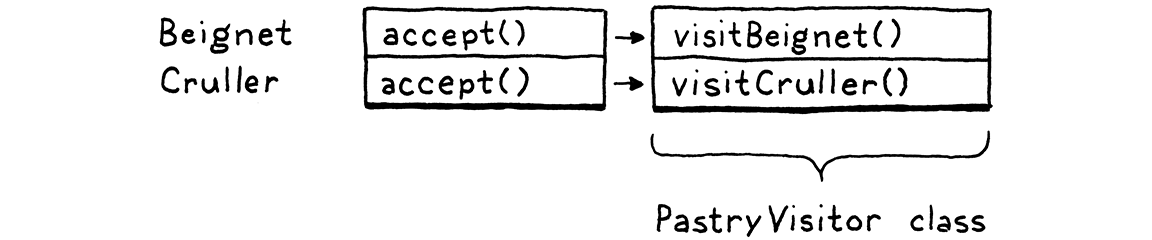
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 package mainimport "fmt" type Pastry struct {} type Beignet struct { Pastry } type Cruller struct { Pastry } type PastryAceept interface { accept(vistor PastryVistor) } func (beignet Beignet) vistor.visitBeignet(beignet) } func (cruller Cruller) vistor.visitCruller(cruller) } type PastryVistor interface { visitBeignet(beignet Beignet) visitCruller(cruller Cruller) } type PastryPrinter struct {}func (printer PastryPrinter) fmt.Printf("beignet: %v\n" , beignet) } func (printer PastryPrinter) fmt.Printf("cruller: %v\n" , cruller) } func main () var beignet Beignet = Beignet{}; var cruller Cruller = Cruller{}; var PastryPrint PastryPrinter beignet.accept(PastryPrint) cruller.accept(PastryPrint) }
这里我以go的interface写了一个访问者模式下代码可能的组织方式,这给了我们两种角度来审视和组织代码
PastryPrinter是PastryVistor的一种实现,这里以PastryPrinter为例
你可以认为PastryPrinter里的每一个函数都属于类下面的方法,这么看代码依旧是面向对象的
但是你如果认为PastryPrinter是一个整体,描述对Pastry的子类们的打印操作,那代码就变成函数式的
当你需要增/改一个类型时,你可以按照面向对象的思维来做,而当你需要增/改一个操作时,你可以遵循函数式编程
在我看来,代码在文件里的排布依然会有绝对的客观因素,而单纯从逻辑上看,你可以认为 无论你(增/改)(类型/函数),都可以认为你实行了非侵入式修改
以PastryPrinter为例
你的仓库不能一会把PastryPrinter的每个函数放在类文件的下面,方便你增/改类型
一会又把PastryPrinter的所有函数集合在一个源文件下,方便你增/改操作函数
这依然存在着一定弊端,我认为这种方案在强面向对象的语言里是一种实现函数式编程的方法,但称不上完美的解决方案,更不用说这种编程方式比较费脑筋了
小实践 这章的结尾,作者给了一个课后习题,用常见的函数式语言实现面向对象编程,那我就拿最熟悉的c了,由于篇幅限制,我尽可能写的简单点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <stdio.h> #include <stdlib.h> typedef struct pet pet ;typedef struct { void (*speak_name) (pet *pet); } pet_operations; struct pet { pet_operations pet_ops; char *name; }; typedef struct { pet dog; } dog; extern dog *init_dog (char *name) ;extern void free_dog (dog *free_dog) ;static pet_operations dog_ops;dog * init_dog (char *name) { dog *new_dog = (dog *)malloc (sizeof (dog)); new_dog->dog.name = name; new_dog->dog.pet_ops = dog_ops; return new_dog; } void free_dog (dog *free_dog) { free (free_dog); } static void dog_speak_name (pet *pet) { printf ("woof! I'm %s\n" , pet->name); } static pet_operations dog_ops = { .speak_name = dog_speak_name };int main () { dog *kaka = init_dog ("kaka" ); kaka->dog.pet_ops.speak_name ((pet *)kaka); }
思路是差不多了,可惜最后调用时的调用链有些过于复杂,而且在从kaka调用的函数最后还得手动传入kaka